Обновление SEO Spider Screaming Frog – версия 14.0
Мы рады запустить Screaming Frog SEO Spider версии 14.0 под внутренним кодовым названием «мания величия».
С момента выпуска версии 13 в июле разработчики были заняты работой над следующим раундом функций для версии 14, основываясь на отзывах пользователей и, как всегда, небольшом внутреннем управлении.
Давайте поговорим о том, что нового в этом выпуске.
1) Темный режим
Возможно, это не самая важная функция в этом выпуске, но она используется на всех скриншотах, поэтому имеет смысл поговорить в первую очередь. Теперь вы можете переключиться в темный режим через «Конфигурация > Пользовательский интерфейс > Тема > Темный».
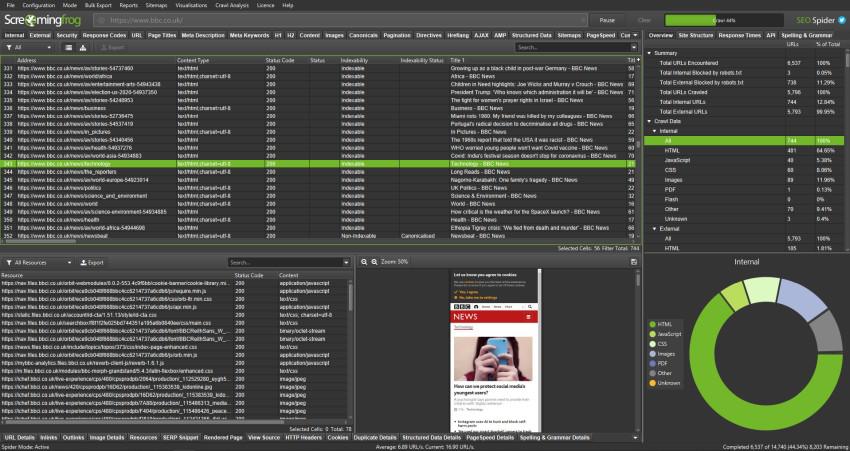
Это не только поможет снизить нагрузку на глаза для тех, кто работает при слабом освещении (все, кто сейчас живет в условиях пандемии), но и выглядит очень круто – и, как предполагаю (сейчас я), значительно повысит ваши технические навыки SEO.
Те, кто не напрягает глаза, могут заметить, что разработчики также изменили некоторые другие элементы стилей и графики, например, те, что находятся на вкладках обзора справа и структуры сайта.
2) Экспорт в Google Таблицы
Теперь вы можете экспортировать прямо в Google Таблицы.
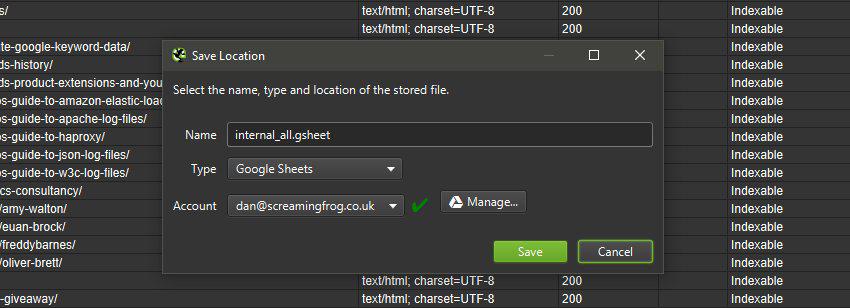
Вы можете добавить несколько учетных записей Google и быстро подключиться к любой, чтобы сохранить данные сканирования, которые появятся на Google Диске в папке Screaming Frog SEO Spider и будут доступны через Таблицы.
Многие из вас уже знают, что Google Таблицы на самом деле не предназначены для масштабирования и имеют ограничение в 5 м ячеек. Это звучит много, но когда у вас по умолчанию 55 столбцов на вкладке Internal (которые могут легко утроиться в зависимости от вашей конфигурации), это означает, что вы можете экспортировать только около 90 тысяч строк (55 x 90 000 = 4950 000 ячеек).
Если вам нужно экспортировать больше, используйте другой формат экспорта, соответствующий размеру (или уменьшите количество столбцов). Стоит отметить что разработчики начали работу над записью на несколько листов, но на самом деле Таблицы не следует использовать таким образом.
Это также было интегрировано в планирование и командную строку. Это означает, что вы можете запланировать сканирование, которое автоматически экспортирует любые вкладки, фильтры, экспорт или отчеты в таблицу на Google Диске.
Вы можете создать папку с отметкой времени на Google Диске или перезаписать существующий файл.
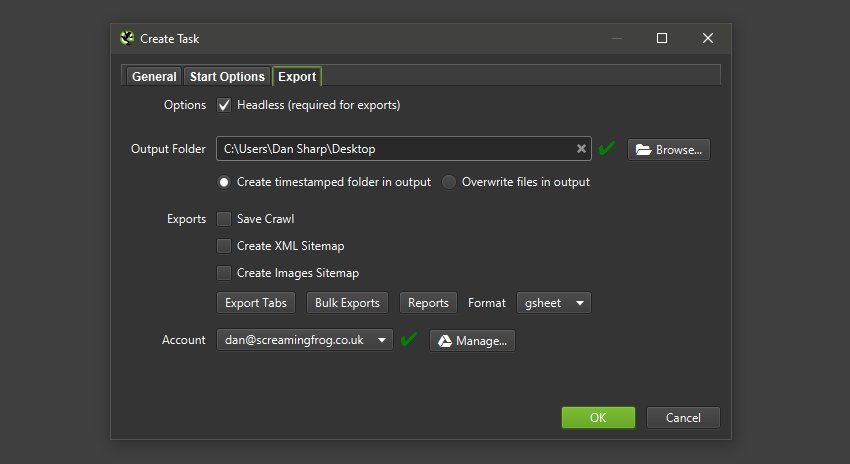
Это должно быть полезно при обмене данными в командах, с клиентами или для отчетов Google Data Studio.
3) Заголовки HTTP
Теперь вы можете хранить, просматривать и запрашивать полные заголовки HTTP. Это может быть полезно при анализе различных сценариев, которые не охватываются извлеченными заголовками по умолчанию, таких как сведения о состоянии кеширования, set-cookie, content-language, политиках функций, заголовках безопасности и т.
Вы можете извлечь их, выбрав «Конфигурация > Паук > Извлечение» и выбрав «Заголовки HTTP». Заголовки запроса и ответа будут показаны полностью на вкладке «Заголовки HTTP» нижнего окна.

Заголовки HTTP-ответа также добавляются в виде столбцов на вкладке Internal, поэтому их можно просматривать, запрашивать и экспортировать вместе со всеми обычными данными сканирования.
Заголовки также можно экспортировать массово через «Массовый экспорт > Интернет > Все заголовки HTTP».
Теперь вы также можете хранить файлы cookie через сканирование. Вы можете извлечь их, выбрав «Конфигурация > Паук > Извлечение» и выбрав «Файлы cookie». Затем они будут полностью показаны на вкладке Cookies в нижнем окне.

Вам нужно будет использовать режим рендеринга JavaScript, чтобы получить точное представление о файлах cookie, которые загружаются на страницу с помощью JavaScript или тегов изображений пикселей.
SEO Spider будет собирать имя файла cookie, значение, домен (первый или сторонний), срок действия, а также такие атрибуты, как secure и HttpOnly.
Затем эти данные могут быть проанализированы в совокупности, чтобы помочь в проверке файлов cookie, например, для GDPR, через «Отчеты > Файлы cookie > Сводка файлов cookie».
Вы также можете выделить несколько URL-адресов одновременно для массового анализа или экспортировать через «Массовый экспорт > Интернет > Все файлы cookie».
Обратите внимание: при выборе сохранения файлов cookie автоматическое исключение, выполняемое SEO Spider для тегов отслеживания Google Analytics, отключается, чтобы обеспечить точное представление всех выпущенных файлов cookie.
Это означает, что это повлияет на вашу аналитическую отчетность, если вы не решите исключить любые скрипты отслеживания из запуска с помощью конфигурации Exclude («Конфигурация > Исключить») или отфильтровать пользовательский агент «Screaming Frog SEO Spider» аналогично исключению PSI в этом FAQ.
5) Агрегированная структура сайта
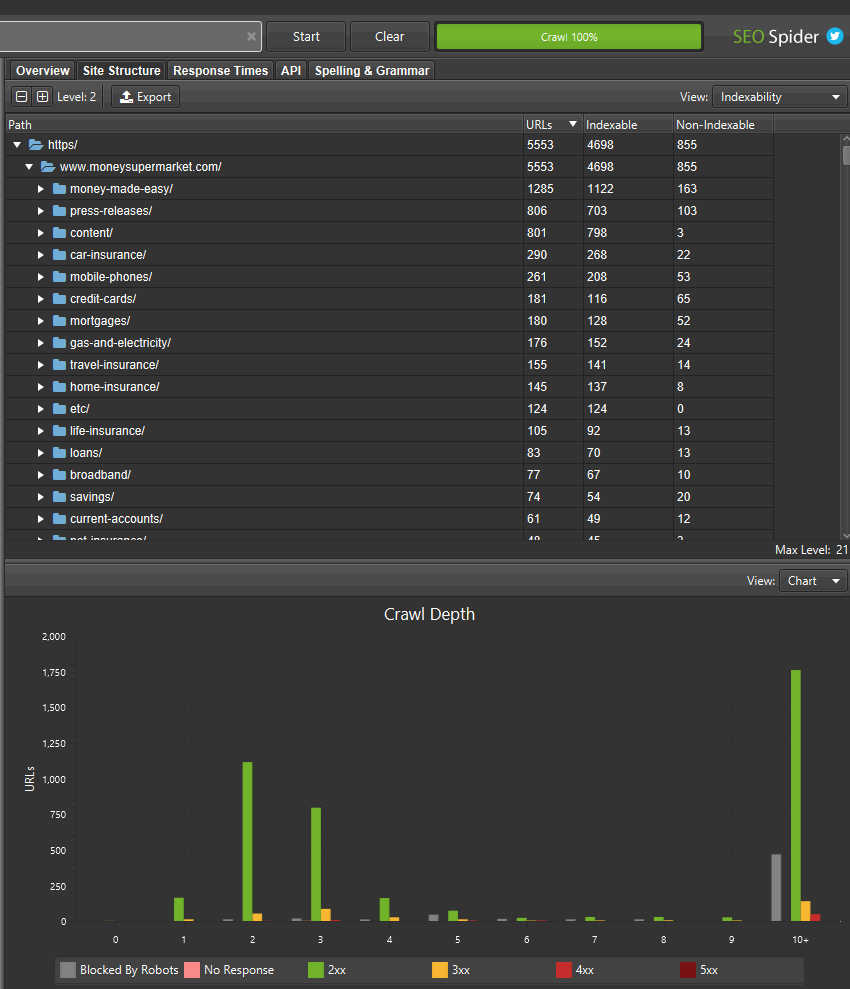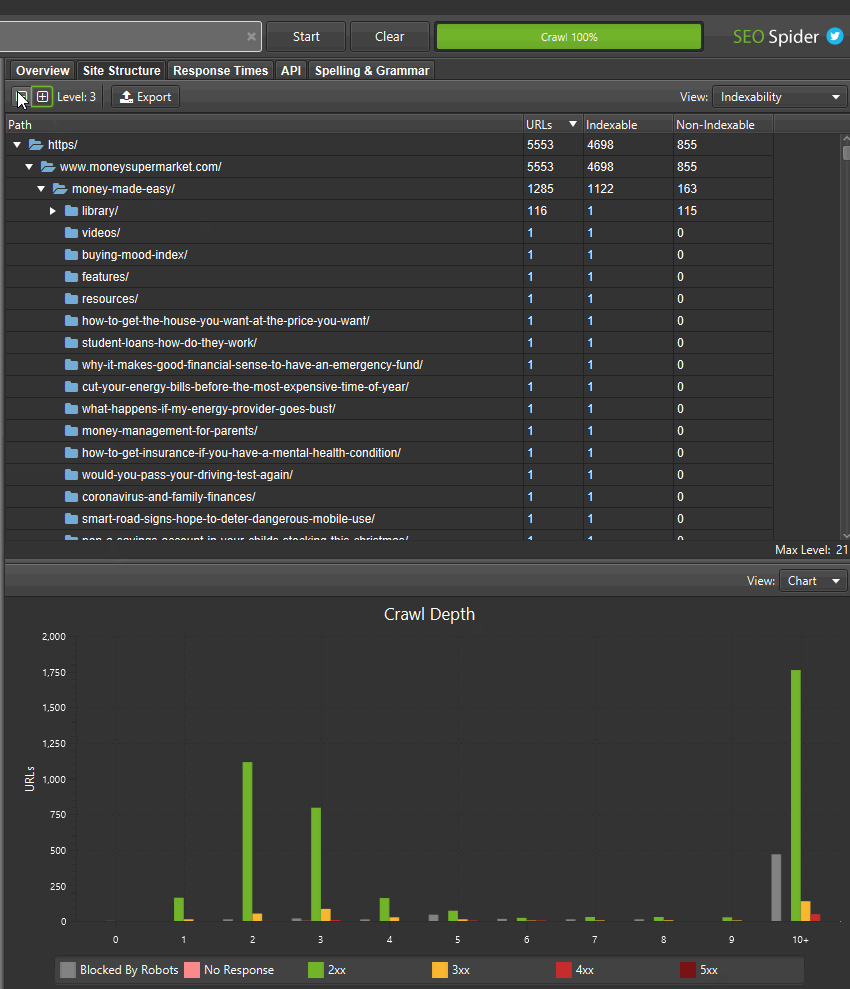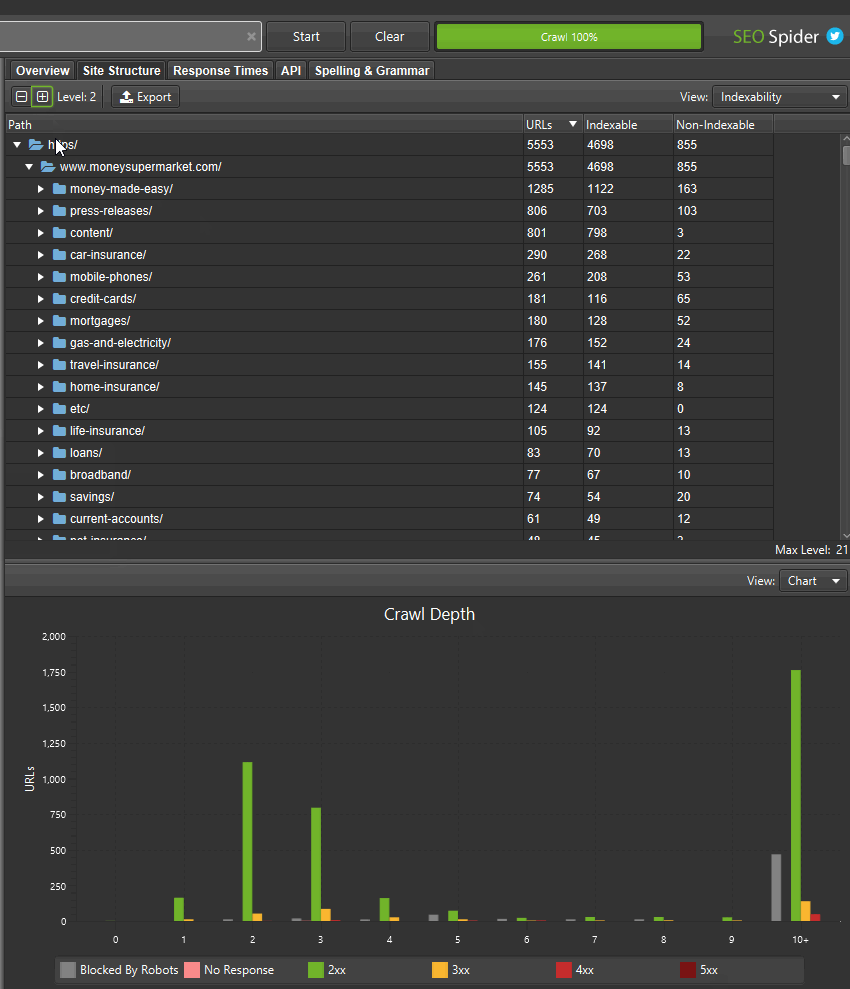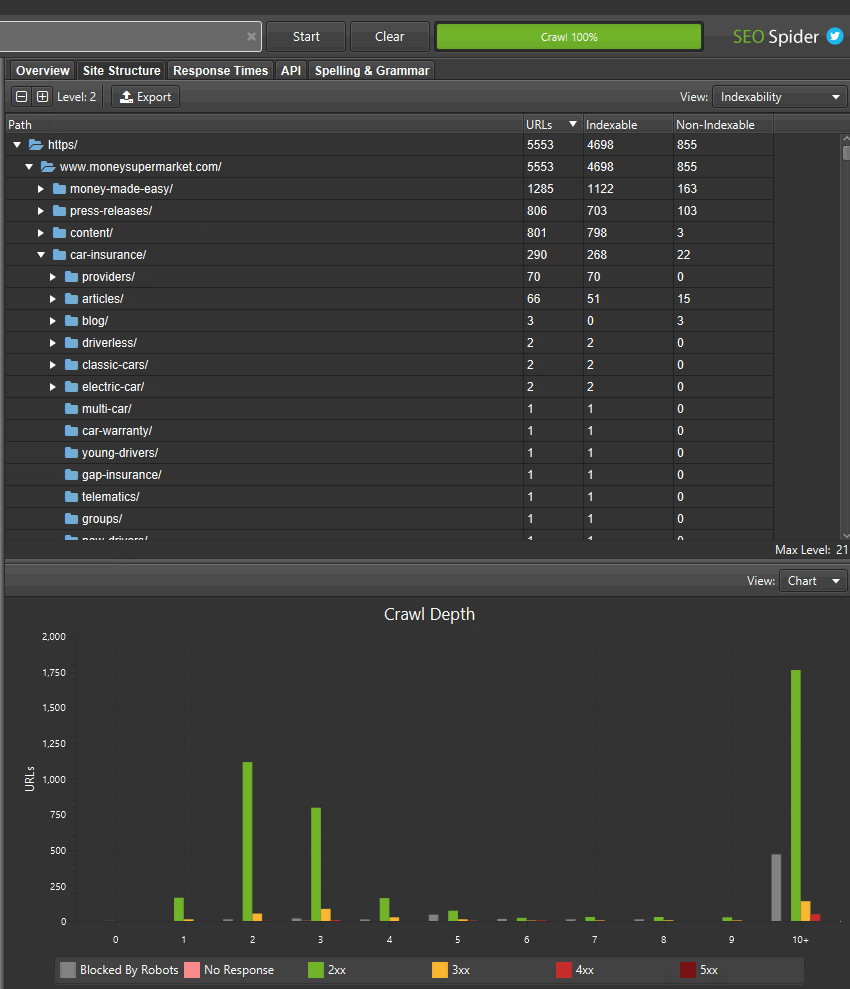
SEO Spider теперь отображает количество URL-адресов, обнаруженных в каждом каталоге, в дереве каталогов (к которому вы можете получить доступ через значок дерева рядом с «Экспорт» на верхних вкладках).
Это помогает лучше понять размер и архитектуру веб-сайта, и некоторые пользователи считают его более логичным в использовании, чем традиционное представление списка.

Наряду с этим обновлением команда разработчиков улучшила правую вкладку «Структура сайта», чтобы отобразить агрегированное представление веб-сайта в виде дерева каталогов. Это помогает быстро визуализировать структуру веб-сайта и с первого взгляда определять, где возникают проблемы, например, индексируемость различных путей.
Если вы нашли области сайта с неиндексируемыми URL-адресами, вы можете переключить «вид», чтобы проанализировать «статус индексируемости» этих различных сегментов пути, чтобы увидеть причины, по которым они считаются неиндексируемыми.
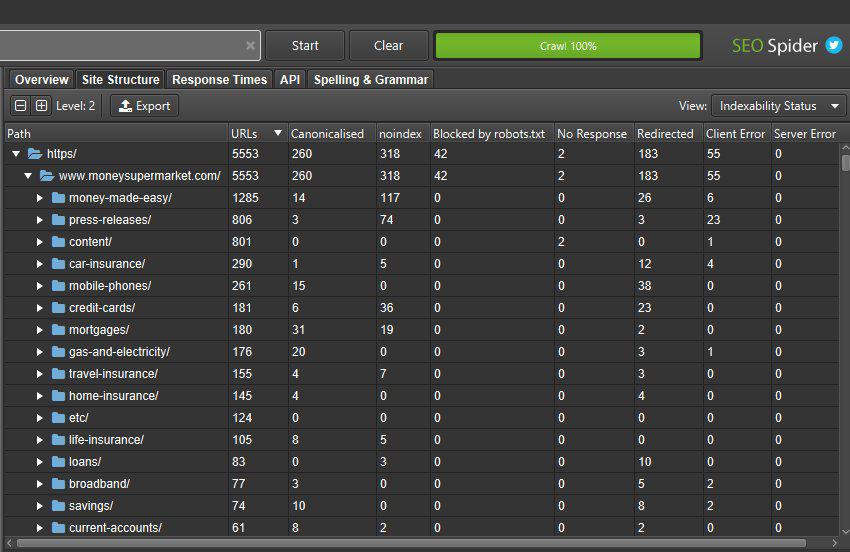
Вы также можете переключить представление на глубину сканирования по каталогам, чтобы помочь выявить любые проблемы с внутренними ссылками на разделы сайта и многое другое.
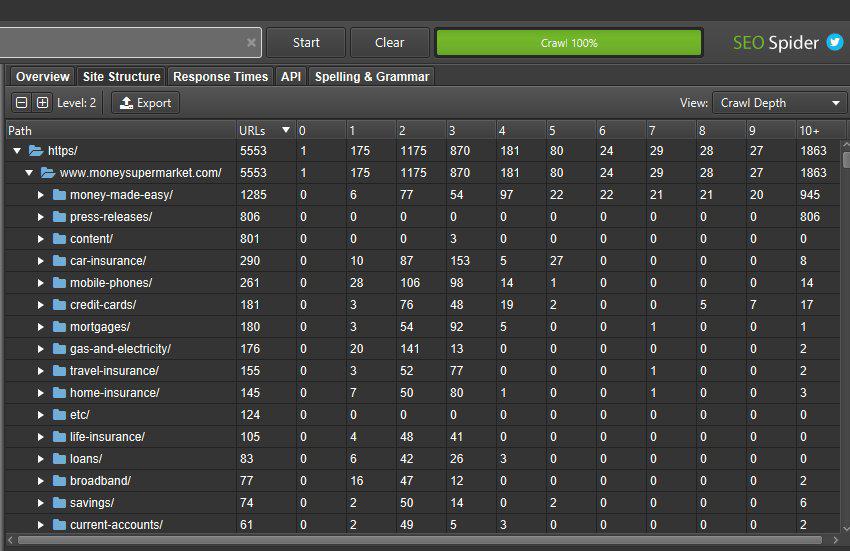
Этот более широкий агрегированный вид веб-сайта должен помочь вам визуализировать архитектуру и принимать более обоснованные решения для различных разделов и сегментов.
6) Новые параметры конфигурации
Предоставлены два новых и важных параметра конфигурации – «Игнорировать неиндексируемые URL-адреса для фильтров на странице» и «Игнорировать URL-адреса с разбивкой на страницы для повторяющихся фильтров».
Оба они включены по умолчанию через «Конфигурация > Паук > Дополнительно» и означают, что неиндексируемые страницы не будут отмечены соответствующими фильтрами на странице для заголовков страниц, мета описаний или заголовков.
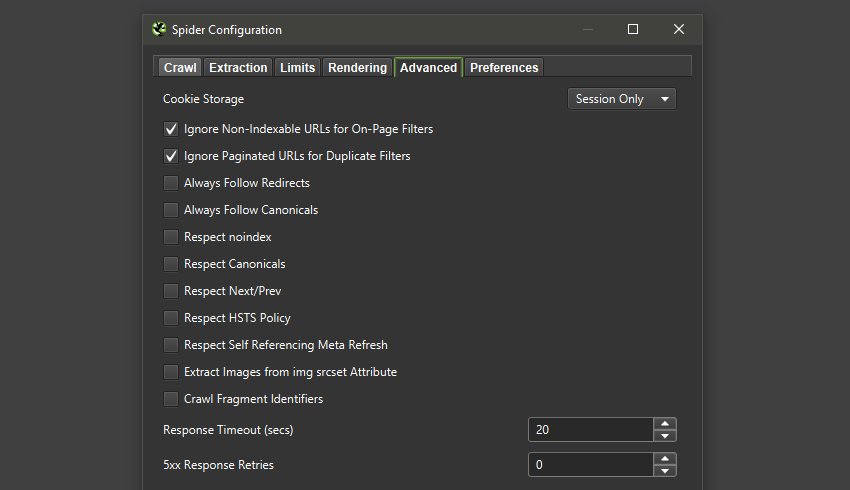
Это означает, что URL-адреса не будут считаться «повторяющимися», «более X символов» или «менее X символов», если, например, они являются noindex и, следовательно, не индексируются. Страницы, разбитые на страницы, также не будут помечены на дублирование.
Если вы сканируете промежуточный веб-сайт, у которого нет индекса на всех страницах, не забудьте отключить эти параметры.
Эти параметры немного отличаются от параметров конфигурации «здесь », которые вообще исключают появление неиндексируемых URL-адресов. Неиндексируемые URL-адреса по-прежнему будут отображаться в интерфейсе, они просто не будут помечены для соответствующих проблем.
Прочие обновления
Версия 14.0 также включает ряд небольших обновлений и исправлений ошибок, описанных ниже.
- На вкладке «Изображения» появился новый фильтр «Отсутствующий атрибут Alt». Ранее отсутствующие и пустые атрибуты alt появлялись под единственным фильтром «Отсутствующий замещающий текст». Однако может быть полезно разделить их, так как декоративные изображения должны иметь пустой замещающий текст (alt = “”), а не пропускать атрибут alt, который может вызвать проблемы в программах чтения с экрана. См. Наше руководство «Как найти отсутствующий замещающий текст и атрибуты изображения».
- Headless Chrome, используемый при рендеринге JavaScript, был обновлен, чтобы не отставать от вечнозеленого робота Google.
- «Принимать файлы cookie» было изменено на «Хранилище файлов cookie» с тремя вариантами: «Только сеанс», «Постоянный» и «Не хранить». По умолчанию установлено значение «Только сеанс», что имитирует поведение робота Googlebot без сохранения состояния.
- На вкладке «URL-адрес» доступны новые фильтры для решения распространенных проблем, включая множественные косые черты (//), повторяющийся путь, содержит пробелы и URL-адреса, которые могут быть частью внутреннего поиска.
- На вкладке «Безопасность» теперь есть фильтр «Отсутствует заголовок политики безопасного перехода».
- Теперь на вкладках «Внутренняя» и «Безопасность» есть столбец «Версия HTTP», который показывает, под какой версией было выполнено сканирование. Это подготовка к поддержке встроенного сканирования HTTP / 2 с помощью робота Googlebot.
- Теперь вы можете щелкнуть правой кнопкой мыши и «закрыть» или перетащить и переместить порядок вкладок нижнего окна аналогично верхним вкладкам.
- Неиндексируемые URL-адреса теперь не включаются в фильтр «URL-адреса не в Sitemap», так как мы предполагаем, что они не индексируются правильно и поэтому не должны быть помечены. Дополнительную информацию можно найти в нашем руководстве «Как проводить аудит XML-файлов Sitemap ».
- Проверка функции расширенных результатов Google была обновлена в соответствии с постоянно меняющейся документацией.
- Отчет «Сводка функций расширенных результатов Google», доступный через «Отчеты» в меню верхнего уровня, был обновлен и теперь включает «% подходящих» для расширенных результатов на основе обнаруженных ошибок. Этот отчет также включает общее и уникальное количество ошибок и предупреждений, обнаруженных для каждой функции Rich Result, в качестве обзора.
На данный момент это все, и создатели ПО уже начали работу над функциями для версии 15. Если у вас возникнут проблемы, добро пожаловать в службу поддержки.
А теперь скачайте Screaming Frog SEO Spider версии 14.0 и поделитесь с нами своим мнением!
Источник записи: https://www.screamingfrog.co.uk